

Finally, here's a table with the market share of various platforms in February 2019, but it needs to be read with care, since it lists multiple versions of Windows, Android, and ioS/Mac.

The social indicators presented in this chapter illustrate in broad terms how the Nation is faring in selected areas. Indicators are drawn from six domains: economic, demographic and civic, socioeconomic, health, security and safety, and environment and energy. ... These indicators are only a subset of the vast array of available data on conditions in the United States. In choosing indicators for these tables, priority was given to measures that are broadly relevant to Americans and consistently available over an extended period. Such indicators provide a current snapshot while also making it easier to draw comparisons and establishThis section includes a long table stretching over parts of three pages shows many statistics for ten-year intervals since 1960, and also the last few years. For me, tables like this offer a grounding in basic facts and patterns. Here, I'll offer some comparisons drawn from the table over the last half-century or so, from 1960 or 1970 up to the most recent data.
I don’t think economists fully understand the set of constraints that politicians operate under, probably because we have tenure, so we can say whatever we want. The politicians don’t. They constantly have to get approval by the voters, and the voters have different views of economic issues than economists do. So the politicians are sort of stuck between the voters they have to appeal to and the economists who are giving them advice. I think understanding the difficult constraints that politicians operate under would be useful.
In terms of what politicians don’t understand about economists, I think they often turn to (economists) for the wrong set of questions. My mentor, [Princeton University economist] Alan Blinder, coined what he calls Murphy’s Law of economic policy, which says that economists have the most influence where they know the least, and they have the least influence where they know the most.
Politicians are constantly asking us, ‘What’s going to happen next year?’ But we are really bad at forecasting. I understand why people need forecasting, as part of the policy process, but we’re really bad at it, and we’re probably not going to be good any time soon. On the other the hand, there are certain problems where we kind of understand the answer. We understand that rent control is not a particularly good way to run a housing market. We understand that if you want to deal with climate change, you probably want to put a price on carbon. If you have a city that suffers from congestion, we can solve that with congestion pricing.
"Bower thinks that we can teach economics to undergraduates. I disagree. I have concluded reluctantly, after ruminating on it for a long me, that we can't. We can teach about economics, which is a good thing. The undergraduate program in English literature teaches about literature, not how to do it. No one complains, or should. The undergraduate program in art history teaches about painting, not how to do it. I claim the case of economics is similar. Majoring in economics can teach about economics, but not how to do it....
As an empirical scientist I have to conclude from this and other experiences that thinking like an economist is too difficult to be a realistic goal for teaching. I have taught economics, man and boy, for nearly a century, and I tell you that it is the rare, gifted graduate student who learns to think like an economist while still in one of our courses, and it takes a genius undergraduate (Sandy Grossman, say, who was an undergraduate when I came to Chicago in 1968). Most of the economists who catch on do so long after graduate school, while teaching classes or advising governments: that's when I learned to think like an economist, and I wonder if your experience is not the same.
"Let me sharpen the thought. I think economics, like philosophy, cannot be taught to nineteen-year olds. It is an old man's field. Nineteen-year olds are, most of them, romantics, capable of memorizing and emoting, but not capable of thinking coldly in the cost-and-benefit way. Look for example at how irrational they are a few years later when getting advice on post-graduate study. A nineteen-year old has intimations of immortality, comes directly from a socialized economy (called a family), and has no feel on his pulse for those tragedies of adult life that economists call scarcity and choice. You can teach a nineteen-year old all the math he can grasp, all the history he can read, all the Latin he can stand. But you cannot teach him a philosophical subject. For that he has to be, say twenty-five, or better, forty-five. ...In practical terms, the standard principles of economics course is a long march through a bunch of conceptual ideas: opportunity cost, supply and demand, perfect and imperfect competitions, comparative advantage and international trade, externalities and public goods, unemployment and inflation, monetary and fiscal policy, and more. The immediate concern of most students is to master those immediate tools--what McCloskey calls learning "about" economics. But I do think that in the process of learning "about," many principles students get a meaningful feeling for a the broader subject and mindset. In the introduction to my own principles textbook, I write:
There’s an old joke that economics is the science of taking what is obvious about human behavior and making it incomprehensible. Actually, in my experience, the process works in the other direction. Many students spend the opening weeks of an introductory economics course feeling as if the material is difficult, even impossible, but by the middle and the end of the class, what seemed so difficult early in the term has become obvious and straightforward. As a course in introductory economics focuses on one lesson after another and one chapter after another, it’s easy to get tunnel vision. But when you raise your eyes at the end of class, it can be quite astonishing to look back and see how far you have come. As students apply the terms and models they have learned to a series of real and hypothetical examples, they often find to their surprise that they have also imbibed a considerable amount about economic thinking and the real-world economy. Learning always has an aspect of the miraculous.Thus, I agree with McCloskey that truly "thinking like an economist" is a very rare outcome in a principles course, and unless you are comfortable as a teacher with setting a goal that involves near-universal failure, it's not a useful goal for instructors. But it also seems true to me that the series of topics in a conventional principles of economics course, and how they build on each other, does for many students combine to form a comprehensible narrative by the end of the class. The students are not thinking like economists. But they have some respect and understanding for how economist think.


"For 11-month-old children, minimum staff-to-child ratios ranged from 1:3 in Kansas to 1:6 in Arkansas, Georgia, Louisiana, Nevada, and New Mexico in 2014. For 35-month-old children, they ranged from 1:4 in the District of Columbia to 1:12 in Louisiana. For 59-month-old children, they ranged from 1:7 in New York and North Dakota to 1:15 in Florida, Georgia, North Carolina, and Texas. Assuming an average hourly wage of $15 for staff members (inclusive of benefits and payroll taxes paid by the employer), the minimum cost for staff per child per hour would range from $2.50 in the most lenient State to $5 in the most stringent State for 11-month-old children, from $1.25 to $3.75 for 35-month old-children, and from $1.00 to $2.14 for 59 month-old children."Here's a figure illustrating the theme.

Wages are based on the local labor market demand for the employees’ skills and qualifications, as well as the availability of workers in the field. Regulations that require higher-level degrees or other qualifications drive up the wages required to hire and retain staff, increasing the cost of child care. Though recognizing that some facilities are exempt from these requirements, all States set requirements for minimum ages and qualifications of staff, including some that require a bachelor’s degree for lead child care teachers. Other staff-related regulations that can drive up costs include required background checks and training requirements. In addition to standards regarding staff, many States set minimum requirements for buildings and facilities, including regulating the types and frequency of environmental inspections and the availability of indoor and outdoor space.The report looks at some studies of the effects of these rules. One study estimates "that decreasing the maximum number of infants per staff member by one (thereby increasing the minimum staff-to-child ratio) decreases the number of center-based care establishments by about 10 percent. Also, each additional year of education required of center directors decreases the supply of care centers by about 3.5 percent." The point, of course, is not that states should all move unquestioningly to lower staffing levels. It's that states should question their rules, and look at practices elsewhere, bearing in mind that the costs of rules hit harder for those with lower incomes.
The Trump Administration has mitigated these work disincentives by substantially bolstering child care programs for low-income families. In 2018, the CCDBG [Child Care and Development Block Grant] was increased by $2.4 billion, and this increase was sustained in 2019. The Child Care and Development Fund, which includes CCDBG and other funds, distributed a total of $8.1 billion to States to offer child care subsidies to low-income families who require child care in order to work, go to school, or enroll in training programs. In addition, Federal child care assistance is offered through TANF, Head Start, and other programs.There are also mentions of how programs like Supplemental Nutrition Assistance Program (SNAP, or "food stamps") and the Earned Income Tax Credit can help to make child care more affordable. The Child Tax Credit, which was increased in the 2017 tax legislation, including "the refundable component of the CTC for those with earnings but no Federal income tax liability." There's also a child and dependent care tax credit.
- Both unchecked climate change and any potential deployment of solar geoengineering (SG) are governed by processes that are currently unknowable; i.e., either is afflicted with ignorance.
- Risk, uncertainty, and ignorance are often greeted with the precautionary principle: “do not proceed.” Such inertia helps politicians and bureaucrats avoid blame. However, the future of the planet is too important a consequence to leave to knee-jerk caution and strategic blame avoidance. Rational decision requires the equal weighting of errors of commission and omission.
- Significant temperature increase, at least to the 2°C level, is almost certainly in our planet’s future. This makes research on SG a prudent priority, with experimentation to follow, barring red-light findings. ...
Consider the decision of whether to enroll in a high-risk medical trial. Faced with a bad case of cancer, the standard treatment is high-dose chemotherapy. Now consider as an alternative treatment an experimental bone-marrow transplant. the additional treatment mortality of the trial, of say 4 percentage points, is surely an important aspect of the decision – but so should be the gain in long-run survival probability. If that estimated gain is greater than 4 percentage points, say 10 or even “only” 6 percentage points, a decision maker with the rational goal of maximizing the likelihood of survival should opt for the experimental treatment.
All too often, however, psychology intervenes, including that of doctors. Errors of commission get weighted more heavily; expected lives are sacrificed. The Hippocratic Oath bans the intention of harm, not its possibility. Its common misinterpretation of “first do no harm” enshrines the bias of overweighing errors of commission. To be sure, errors of commission incur greater blame or self-blame than those of omission when something bad happens, a major source of their greater weight. But blame is surely small potatoes relative to survival, whether of a patient or of the Earth. Hence, we assert once again, italics and all: Where climate change and solar geoengineering are concerned, errors of commission and omission should be weighted equally.
That also implies that the dangers of SG [solar geoengineering] – and they are real – should be weighed objectively and dispassionately on an equal basis against the dangers of an unmitigated climate path for planet Earth. The precautionary principle, however tempting to invoke, makes little sense in this context. It would be akin to suffering chronic kidney disease, and being on the path to renal failure, yet refusing a new treatment that has had short-run success, because it could have long-term serious side effects that tests to date have been unable to discover. Failure to assiduously research geoengineering and, positing no red-light findings, to experiment with it would be to allow rising temperatures to go unchecked, despite great uncertainties about their destinations and dangers. That is hardly a path of caution.For an earlier post on this topic, see "Geoengineering: Forced Upon Us?" (May 11, 2015).
We conclude, based on our review of the articles in this special issue and the broader literature, that it is time to stop using the term “statistically significant” entirely. Nor should variants such as “significantly different,” “p < 0.05,” and “nonsignificant” survive, whether expressed in words, by asterisks in a table, or in some other way. Regardless of whether it was ever useful, a declaration of “statistical significance” has today become meaningless. ... In sum, `statistically significant'—don’t say it and don’t use it.The special issue is then packed with 43 essays from a wide array of experts and fields on the general theme of "if we eliminate the language of statistical significance, what comes next?"
The econometric art as it is practiced at the computer terminal involves fitting many, perhaps thousands, of statistical models. One or several that the researcher finds pleasing are selected for re- porting purposes. This searching for a model is often well intentioned, but there can be no doubt that such a specification search in-validates the traditional theories of inference. ... [I]n fact, all the concepts of traditional theory, utterly lose their meaning by the time an applied researcher pulls from the bramble of computer output the one thorn of a model he likes best, the one he chooses to portray as a rose. The consuming public is hardly fooled by this chicanery. The econometrician's shabby art is humorously and disparagingly labelled "data mining," "fishing," "grubbing," "number crunching." A joke evokes the Inquisition: "If you torture the data long enough, Nature will confess" ... This is a sad and decidedly unscientific state of affairs we find ourselves in. Hardly anyone takes data analyses seriously. Or perhaps more accurately, hardly anyone takes anyone else's data analyses seriously."Economists and other social scientists have become much more aware of these issues over the decades, but Leamer was still writing in 2010 ("Tantalus on the Road to Asymptopia," Journal of Economic Perspectives, 24: 2, pp. 31-46):
Since I wrote my “con in econometrics” challenge much progress has been made in economic theory and in econometric theory and in experimental design, but there has been little progress technically or procedurally on this subject of sensitivity analyses in econometrics. Most authors still support their conclusions with the results implied by several models, and they leave the rest of us wondering how hard they had to work to find their favorite outcomes ... It’s like a court of law in which we hear only the experts on the plaintiff’s side, but are wise enough to know that there are abundant for the defense.Taken together, these issues suggest that a lot of the findings in social science research shouldn't be believed with too much firmness. The results might be true. They might be a result of a researcher pulling out "from the bramble of computer output the one thorn of a model he likes best, the one he chooses to portray as a rose." And given the realities of real-world research, it seems goofy to say that a result with, say, only a 4.8% probability of happening by chance is "significant," while if the result had a 5.2% probability of happening by chance it is "not significant." Uncertainty is a continuum, not a black-and-white difference.
[A] label of statistical significance does not mean or imply that an association or effect is highly probable, real, true, or important. Nor does a label of statistical nonsignificance lead to the association or effect being improbable, absent, false, or unimportant. Yet the dichotomization into “significant” and “not significant” is taken as an imprimatur of authority on these characteristics. In a world without bright lines, on the other hand, it becomes untenable to assert dramatic differences in interpretation from inconsequential differences in estimates. As Gelman and Stern (2006) famously observed, the difference between “significant” and “not significant” is not itself statistically significant.But as they recognize, criticizing is the easy part. What is to be done instead? And here, the argument fragments substantially. Did I mention that there were 43 different responses in this issue of the American Statistician?
"Authors identified four general instances. Some allowed that, while p-value thresholds should not be used for inference, they might still be useful for applications such as industrial quality control, in which a highly automated decision rule is needed and the costs of erroneous decisions can be carefully weighed when specifying the threshold. Other authors suggested that such dichotomized use of p-values was acceptable in model-fitting and variable selection strategies, again as automated tools, this time for sorting through large numbers of potential models or variables. Still others pointed out that p-values with very low thresholds are used in fields such as physics, genomics, and imaging as a filter for massive numbers of tests. The fourth instance can be described as “confirmatory setting[s] where the study design and statistical analysis plan are specified prior to data collection, and then adhered to during and after it” ... Wellek (2017) says at present it is essential in these settings. “[B]inary decision making is indispensable in medicine and related fields,” he says. “[A] radical rejection of the classical principles of statistical inference…is of virtually no help as long as no conclusively substantiated alternative can be offered.”The deeper point here is that there are situation where a researcher or a policy-maker or an economic needs to make a yes-or-no decision. When doing quality control, is it meeting the standard or not? when the Food and Drug Administration is evaluating a new drug, does it approve the drug or not? When a researcher in genetics is dealing with a database that has thousands of genes, there's a need to focus on a subset of those genes, which means making yes-or-no decisions on which genes to include a certain analysis.
P-values are part of a rule-based structure that serves as a bulwark against claims of expertise untethered from empirical support. It can be changed, but we must respect the reason why the statistical procedures are there in the first place ... So what is it that we really want? The ASA statement says it; we want good scientific practice. We want to measure not just the signal properly but its uncertainty, the twin goals of statistics. We want to make knowledge claims that match the strength of the evidence. Will we get that by getting rid of P−values? Will eliminating P−values improve experimental design? Would it improve measurement? Would it help align the scientific question with those analyses? Will it eliminate bright line thinking? If we were able to get rid of P-values, are we sure that unintended consequences wouldn’t make things worse? In my idealized world, the answer is yes, and many statisticians believe that. But in the real world, I am less sure.
"Printing was not only a new technology: it also introduced new forms of competition into European society. Most directly, printing was one of the first industries in which production was organised by for-profit capitalist firms. These firms incurred large fixed costs and competed in highly concentrated local markets. Equally fundamentally – and reflecting this industrial organisation – printing transformed competition in the ‘market for ideas’. Famously, printing was at the heart of the Protestant Reformation, which breached the religious monopoly of the Catholic Church. But printing’s influence on competition among ideas and producers of ideas also propelled Europe towards the scientific revolution.While Gutenberg’s press is widely believed to be one of the most important technologies in history, there is very little evidence on how printing influenced the price of books, labour markets and the production of knowledge – and no research has considered how the economics of printing influenced the use of the technology."
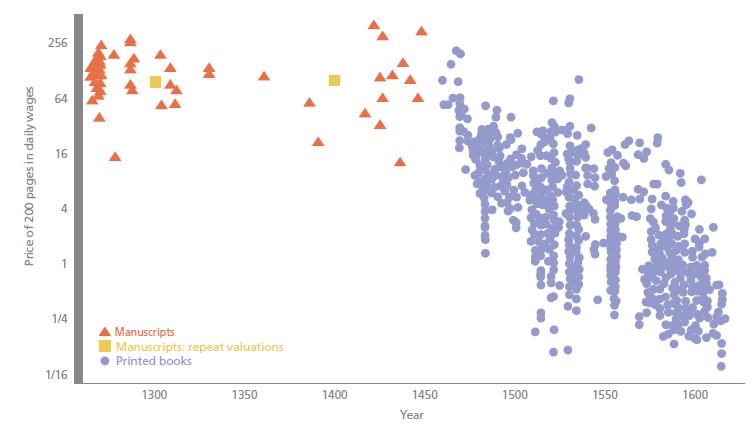
Previous economic research has studied the extensive margin of technology diffusion, comparing the development of cities that did and did not have printing in the late 1400s ... Printing provided a new channel for the diffusion of knowledge about business practices. The first mathematics texts printed in Europe were ‘commercial arithmetics’, which provided instruction for merchants. With printing, a business education literature emerged that lowered the costs of knowledge for merchants. The key innovations involved applied mathematics, accounting techniques and cashless payments systems.It is impossible to avoid wondering if economic historians in 50 or 100 years will be looking back on the spread of internet technology, and how it affected patterns of technology diffusion, human capital, and social beliefs--and how differing levels of competition in the market may affect these outcomes.
The evidence on printing suggests that, indeed, these ideas were associated with significant differences in local economic dynamism and reflected the industrial structure of printing itself. Where competition in the specialist business education press increased, these books became suddenly more widely available and in the historical record, we observe more people making notable achievements in broadly bourgeois careers.









Consider a cohort of 100 students arriving in the ninth grade:
- Of the 100, 18 of them won’t graduate on time from high school
- Of the 82 who do graduate, 25 won’t enroll in higher education
- Of the 57 who do enroll, 29 won’t earn even an associate’s degree after six years
- Of the 28 who do graduate, 12 will land in jobs that do not require a degree
- Only 16 will successfully navigate the high school to college to career pipeline—the current aim of the education system.

"There are many types of agglomeration economies in consumption and we really know very little about them still but my assessment is that cities are the most welfare enhancing human innovation in history: they empowered the division of labour, the invention of money, trade and technical inventions like the wheel – let alone government, the arts or culture."Why Land is Regaining Importance in Economic Analysis
"Classical economists devoted far more effort to trying to understand the returns to land than they did to labour or capital: it was both the most important asset and the most important factor of production. When Adam Smith was writing only about 12 percent of Europe’s population lived in cities and even in the most industrialised country, Britain, the value of agricultural land was about 3 times that of annual GDP. But as the value of other assets increased, interest in land diminished so that by about 1970 really only agricultural economists and a few urban economists were interested in it: and they did not talk to each other. But by 2010 residential property, mostly the land on which houses sat, was worth three times as much as British GDP. By the end of 2013 houses accounted for 61 percent of the UK’s net worth: up from 49 percent 20 years ago. Land, now urban land, is valuable, so there is renewed interest."Urban Policy Often Misses the Problems of the Modern City
"Luckily cities are so resilient because urban policy is generally so bad! ... Policy has been dominated by physical and design ways of thinking: great for building those fantastic innovations of the 19th Century – sewers or water supply. But not useful for facilitating urban growth and offsetting for the costs of city size. We know cities keep on getting more productive the bigger they are but some costs – the price of space, congestion, for example – also increase with city size. So urban policy should offset for those costs. Instead it mainly increases them. Popular policies of densification and containment restrict the supply of space, increasing its price as cities grow so we forego socially valuable agglomeration economies. Another popular policy – height restrictions – reduces gains from ‘vertical’ agglomeration economies."
"In the making of the wages contract the individual laborer is at a disadvantage. He has something which he must sell and which his employer is not obliged to take, since he [that is, the employer] can reject single men with impunity. ... A period of idleness may increase this disability to any extent. The vender of anything which must be sold at once is like a starving man pawning his coat—he must take whatever is offered."In the last few years, an idea has emerged that the same government agencies that are supposed to be concerned about monopoly power--that is, when dominant firms in an industry can take advantage of the lack of competition to raise the prices paid by consumers--should also be concerned about "monopsony" power--that is, when dominant firms in an industry can take advantage of the lack of competition to reduce the wages paid to workers. Eric A. Posner, Glen Weyl and Suresh Naidu offer a useful overview of this line of thought in "Antitrust Remedies for Labor Market Power," published in the Harvard Law Review. (132 Harv. L. Rev. 536, December 2018). My own sense is that their discussion of the power imbalance in labor markets is fully persuasive, but it also seems to me that antitrust is at most a very partial and incomplete way of addressing these issues.
But there is reason to believe that labor markets are more vulnerable to monopsony than products markets are to monopoly, thanks to a different literature in economics. This literature, for which Professors Lloyd Shapley and Alvin Roth were awarded the Nobel Prize, emphasizes the importance of matching for labor markets.The key point is that in labor markets, unlike in product markets, the preferences of both sides of the market affect whether a transaction is desirable.
Compare buying a car in the product market and searching for a job. Both are important, high-stakes choices that are taken with care. However, there is a crucial difference. In a car sale, only the buyer cares about the identity, nature, and features of the product in question — the car. The seller cares nothing about the buyer or (in most cases) what the buyer plans do with the car. In employment, the employer cares about the identity and characteristics of the employee and the employee cares about the identity and characteristics of the employer. Complexity runs in both directions rather than in one. Employers search for employees who are not just qualified, but also who possess skills and personality that are a good match to the culture and needs of that employer. At the same time, employees are looking for an employer with a workplace and working conditions that are a good match for their needs, preferences, and family situation. Only when these two sets of preferences and requirements “match” will a hire be made.
This two-sided differentiation is why low-skill workers may be as or even more vulnerable to monopsony than high-skill workers, despite possibly being less differentiated for employers. Low-skill workers may have less access to transportation, well-situated housing markets, child care options, and job information, and be more dependent on local, informal networks, all of which make jobs less substitutable and employers more differentiated.
This dual set of relevant preferences means that labor markets are doubly differentiated by the idiosyncratic preferences of both employers and workers. In some sense this dual set of preferences “squares” the differentiation that exists in product markets, naturally making labor markets thinner than product markets. This relative thinness means that the cost of entering a transaction — in relation to the gains from trade — is on average greater in employment markets than in product markets because people are not as interchangeable as goods.
These matching frictions both cause and reinforce the typically long-term nature of employment relationships compared to most product purchases, leading to significant lock-in within employment relationships. They are also reinforced by the more geographically constrained nature of labor markets. In our increasingly digital and globalized world, products are easily shipped around the country and world; people are not. While traveling is easier than in the past, and telecommuting has become more common, labor markets remain extremely local while most product markets are regional, national, or even global.Most jobs still require physical proximity to the employer, greatly narrowing the geographic scope of most labor markets, given that many workers are not willing to move away from family to take a job. Two-income families further complicate these issues because each spouse must find a job in the area in which the other can, further narrowing labor markets. Together these factors naturally make labor markets highly vulnerable to monopsony power, much more vulnerable than most product markets are to monopoly power.
Our present business landscape exhibits a number of extremely powerful employers as a result of the neglect of mergers and other anticompetitive behavior in labor markets. While a more detailed examination would be needed to draw any firm conclusions, antitrust investigations into massive employers (such as Compass Group, Accenture, Amazon, Uber, and Walmart), as well as platform-based firms that receive vast flows of valuable data services without any compensation (such as Facebook and Google), seem warranted. It may be that some of these firms have achieved such powerful monopsonies that they should be broken up.Again, the argument here is not that consumers would benefits from breaking up these firms, but that it should be considered on behalf of workers, with the belief that if these firms operated with more competitors, they would need to pay higher wages. I'm open to more evidence on this point, but I'm unpersuaded by the existing evidence. It seems to me that the more direct approach to addressing the generalized power imbalance against workers is to pursue various "active labor market policies" that provide assistance with job search, relocation, and retraining, as well as doing whatever we can to run a "high pressure" economy where unemployment rates are low, so that workers are both in demand and have some plausible alternative options if they want or need to switch employers.
"Just as ambassadors are supposed to faithfully represent the perspective of their nations, the instructor in an introductory course (and intermediate courses as well) should faithfully represent the views shared by the majority of professional economists. ... This perspective of instructor as ambassador raises the question of what instructors should do if they hold views far from the mainstream of the economics profession. If you are an Austrian or Marxist economist, for example, what should you do if asked to teach an introductory course? In my view, there are only two responsible courses of action. One is to sublimate your own views and spend most of the course teaching what the mainstream believes, even if you disagree with it. Because many introductory students will take only one or two courses in economics throughout their educations, it would be pedagogical malpractice, in my judgment, to focus on an idiosyncratic minority viewpoint. The other responsible course of action is to avoid teaching introductory (and even intermediate) courses entirely."I very much agree with this sentiment. But I'd also add that there should be some room, at least at larger universities, for some nonstandard overviews of economics. For example, many schools have freshman seminars taught by regular faculty that focus on writing, but with content specific to the professor. Or departments could offer some intro-level courses, without prerequisites, that aren't the standard course. One would probably need to specify that these alternative courses would not be a good preparation for intermediate micro and intermediate macro to follow. But carving out and preserving some room for experimentation at the intro level seems potentially useful.
"Haven’t supply and demand always been at the center of the introductory course? Surprisingly, no. The first edition of Paul Samuelson's great text, published in 1948 and 608 pages long, did not introduce supply and demand curves until page 447. That is in part because Samuelson, writing in the shadow of the Great Depression, began his book by emphasizing Keynesian macroeconomics. As the book was revised over many editions, standard microeconomic tools became more prominent. But even today, many introductory courses do not develop the framework of supply and demand as fully as they should. In particular, welfare economics is sometimes not given sufficient coverage. The basic tools of welfare economics are consumer surplus and producer surplus, which are natural extensions of supply and demand."Pretty much all modern intro textbooks are the intellectual children of Samuelson's 1948 text, just revised and updated in various ways. My understanding is that if you go back before that textbook, it was common for intro economics courses to have almost no graphs at all--whether supply-and-demand or otherwise. Following Samuelson, it was also standard to do macro before micro, which seemed based on the assumption that macro had more of a connection to current events and would be an easier way to hook intro students into the subject.
"For many years, Otto Eckstein ran the introductory course at Harvard. Unfortunately, I never met him as he passed away just before I joined the faculty. But I have heard one of his aphorisms. Apparently, Otto often told section leaders, `The less you teach them, the more they learn.' What I believe he meant by this is that instructors should avoid overwhelming introductory students with too much information all at once. ... As economists, we teach our students about scarcity. As instructors and textbook authors, we should remember that student time is a scarce resource. We must avoid making our courses encyclopedic. That means taking out all of the easily ignored details and stressing the big ideas. The main goal of the introductory course is not to produce future economists but to produce well-informed citizens. Any topic that a person does not need to understand to intelligently follow the news is a plausible candidate for omission. One risk when simplifying matters for students is oversimplification, losing too much of the nuance that economists bring to an issue. But given the difficulty some students have learning basic economics, it is a bigger risk to overcomplicate the analysis early in the course."In writing a book, there are ongoing pressures to add more. Every reader has a pet topic, or a pet example, or a pet caveat, that would only take another page. A standard response is to write a textbook with the idea that certain chapters will be "core," while other instructors can be dropped by professors if they prefer. In my own textbook, for example, there is a chapter on imperfect information and insurance, and another chapter on financial markets, which can be dropped. In one of the macro chapters, I include the Keynesian cross diagram for teaching about macro in the short-run, but I place it as the second half of a chapter so that it can be smoothly omitted if a professor desires.
"One possibility is to have the fixed costs of production paid by a foundation grant (I am looking at you, Bill Gates) and then make the digital book freely available. This is similar to the common suggestion that newspapers like The New York Times should move from for-profit to non-profit status and then be supported by charitable donors, much like National Public Radio. Yet I am skeptical that this reform would improve on the status quo of the textbook market. After all, the current for-profit educational publishers are not that profitable, and there is no reason to think that a non-profit entity would find cost savings that have eluded existing publishers. I am afraid that the only way to substantially cut costs would be to reduce quality, which would not be in the students’ interests."OpenStax is an organization that makes digital books freely available for a wide range of college courses, including the Economics book in which I played a role. It is indeed partly funded by the Gates Foundation. Mankiw suggests that "free" books may have an undesirable quality tradeoff.
"If you are thinking about writing a textbook, the most important question to ask yourself is: Do you enjoy the process of writing and revising (and revising and revising and…)? Not just tolerate it, but really enjoy it? ... I actually enjoy the triennial revisions of my textbooks, not only because they allow me to update my texts for the ever-changing world but also because they give me the chance to go through the manuscript and tinker some more. I can change `the curve is upward sloping' to “`he curve slopes upward,' saving one word and two syllables! If that edit does not strike you as a life-affirming victory, you are not a writer at heart."This comment reminded me of a couple of others. One was from an economist friend of mine who had serious talks with a publisher about writing a textbook and walked right up to the edge of a sizeable advance payment--before deciding not to go through with it. He told me that in looking the reality of a textbook project in the face: "I discovered that there's a big difference between wanting to write a book and wanting to have written a book."
"The best place to write is by yourself, because writing becomes an escape from the terrible boredom of your own personality. It's the reason that for years I've favored Switzerland, where I look at the telephone and yearn to hear it ring. ... There may be inspired writers for whom the first draft is just right. But anyone who is not certifiably a Milton had better assume that the first draft is a very primitive thing. The reason is simple: Writing is difficult work. Ralph Paine, who managed Fortune in my time, used to say that anyone who said writing was easy was either a bad writer or an unregenerate liar. Thinking, as Voltaire avowed, is also a very tedious thing which men—or women—will do anything to avoid. So all first drafts are deeply flawed by the need to combine composition with thought. Each later draft is less demanding in this regard. Hence the writing can be better."